Habilitar el desarrollo en paralelo con Git y Guardar en carpeta
Este artículo describe los principios del desarrollo en paralelo de modelos (es decir, la posibilidad de que varios desarrolladores trabajen en paralelo en el mismo Data model) y el rol de Tabular Editor en este contexto.
Requisitos previos
- El destino de su Data model debe ser uno de los siguientes:
- SQL Server 2016 (o posterior) Analysis Services Tabular
- Azure Analysis Services
- Fabric/Power BI Premium Capacity/Power BI Premium-per-user con XMLA de lectura/escritura habilitado
- Repositorio Git accesible para todos los miembros del equipo (en las instalaciones o alojado en Azure DevOps, GitHub, etc.)
TOM como código fuente
Tradicionalmente, el desarrollo en paralelo ha sido difícil de implementar en modelos tabulares de Analysis Services y Datasets de Power BI (en este artículo, llamaremos a ambos tipos de modelos "modelos tabulares" para abreviar). Con la introducción de los metadatos del modelo basados en JSON que utiliza el Tabular Object Model (TOM), integrar los metadatos del modelo en el control de versiones se ha vuelto, sin duda, más sencillo.
El uso de un formato de archivo basado en texto permite gestionar los cambios en conflicto de forma ordenada, mediante diversas herramientas de comparación diff que a menudo se incluyen con el sistema de control de versiones. Este tipo de resolución de conflictos de cambios es muy habitual en el desarrollo de software tradicional, donde todo el código fuente se distribuye en una gran cantidad de archivos de texto pequeños. Por este motivo, la mayoría de los sistemas de control de versiones más populares están optimizados para este tipo de archivos, con el fin de detectar cambios y resolver conflictos (de forma automática).
Para el desarrollo de modelos tabulares, el "código fuente" son nuestros metadatos de TOM basados en JSON. Al desarrollar modelos tabulares con versiones anteriores de Visual Studio, el archivo JSON Model.bim se complementaba con información sobre quién modificó qué y cuándo. Esta información simplemente se almacenaba como propiedades adicionales en los objetos JSON de todo el archivo. Esto era problemático, porque no solo era redundante (ya que el propio archivo también tiene metadatos que describen quién fue la última persona que lo editó y cuándo se realizó la última edición), sino que, desde la perspectiva del control de versiones, estos metadatos no tienen ningún significado semántico. En otras palabras, si eliminaras todos los metadatos de modificación del archivo, seguirías teniendo un archivo TOM JSON perfectamente válido, que podrías implementar en Analysis Services o publicar en Power BI, sin afectar a la funcionalidad ni a la lógica de negocio del modelo.
Al igual que con el código fuente en el desarrollo de software tradicional, no queremos que este tipo de información "contamine" los metadatos de nuestro modelo. De hecho, un sistema de control de versiones ofrece una vista mucho más detallada de los cambios realizados, quién los hizo, cuándo y por qué, así que no hay motivo para incluirlo como parte de los archivos que se versionan.
Cuando se creó Tabular Editor por primera vez, no había ninguna opción para deshacerse de esta información en el archivo Model.bim creado por Visual Studio, pero por suerte eso ha cambiado en versiones más recientes. Sin embargo, seguimos teniendo que lidiar con un único archivo monolítico (el archivo Model.bim) que contiene todo el "código fuente" que define el modelo.
Los desarrolladores de Datasets de Power BI lo tienen mucho peor, ya que ni siquiera tienen acceso a un archivo de texto que contenga los metadatos del modelo. Lo mejor que pueden hacer es exportar su Report de Power BI como un archivo de plantilla de Power BI (.pbit), que básicamente es un archivo ZIP que contiene las páginas del Report, las definiciones del Data model y las definiciones de las consultas. Desde la perspectiva de un sistema de control de versiones, un archivo zip es un archivo binario, y los archivos binarios no se pueden hacer diff, comparar ni fusionar de la misma forma que los archivos de texto. Esto obliga a los desarrolladores de Power BI a usar herramientas de terceros o a idear scripts o procesos elaborados para versionar correctamente sus Data models, especialmente si quieren poder fusionar ramas de desarrollo paralelas dentro del mismo archivo.
Tabular Editor busca simplificar este proceso ofreciendo una forma sencilla de extraer únicamente los metadatos semánticamente relevantes del Tabular Object Model, independientemente de si ese modelo es un modelo tabular de Analysis Services o un Dataset de Power BI. Además, Tabular Editor puede dividir estos metadatos en varios archivos más pequeños mediante su función Guardar en carpeta.
¿Qué es Guardar en carpeta?
Como se mencionó anteriormente, los metadatos de un modelo tabular se almacenan tradicionalmente en un único archivo JSON monolítico, normalmente llamado Model.bim, que no es muy adecuado para integrarse con el control de versiones. Dado que el JSON de este archivo representa el Tabular Object Model (TOM), hay una forma sencilla de dividir el archivo en partes más pequeñas: el TOM contiene arrays de objetos en casi todos los niveles, como la lista de tablas de un modelo, la lista de medidas de una tabla, la lista de anotaciones de una medida, etc. Al usar la función Guardar en carpeta de Tabular Editor, estos arrays se eliminan sin más del JSON y, en su lugar, se genera una subcarpeta que contiene un archivo por cada objeto del array original. Este proceso puede anidarse. El resultado es una estructura de carpetas, donde cada carpeta contiene un conjunto de archivos JSON más pequeños y subcarpetas, y que, en términos semánticos, contiene exactamente la misma información que el archivo Model.bim original:
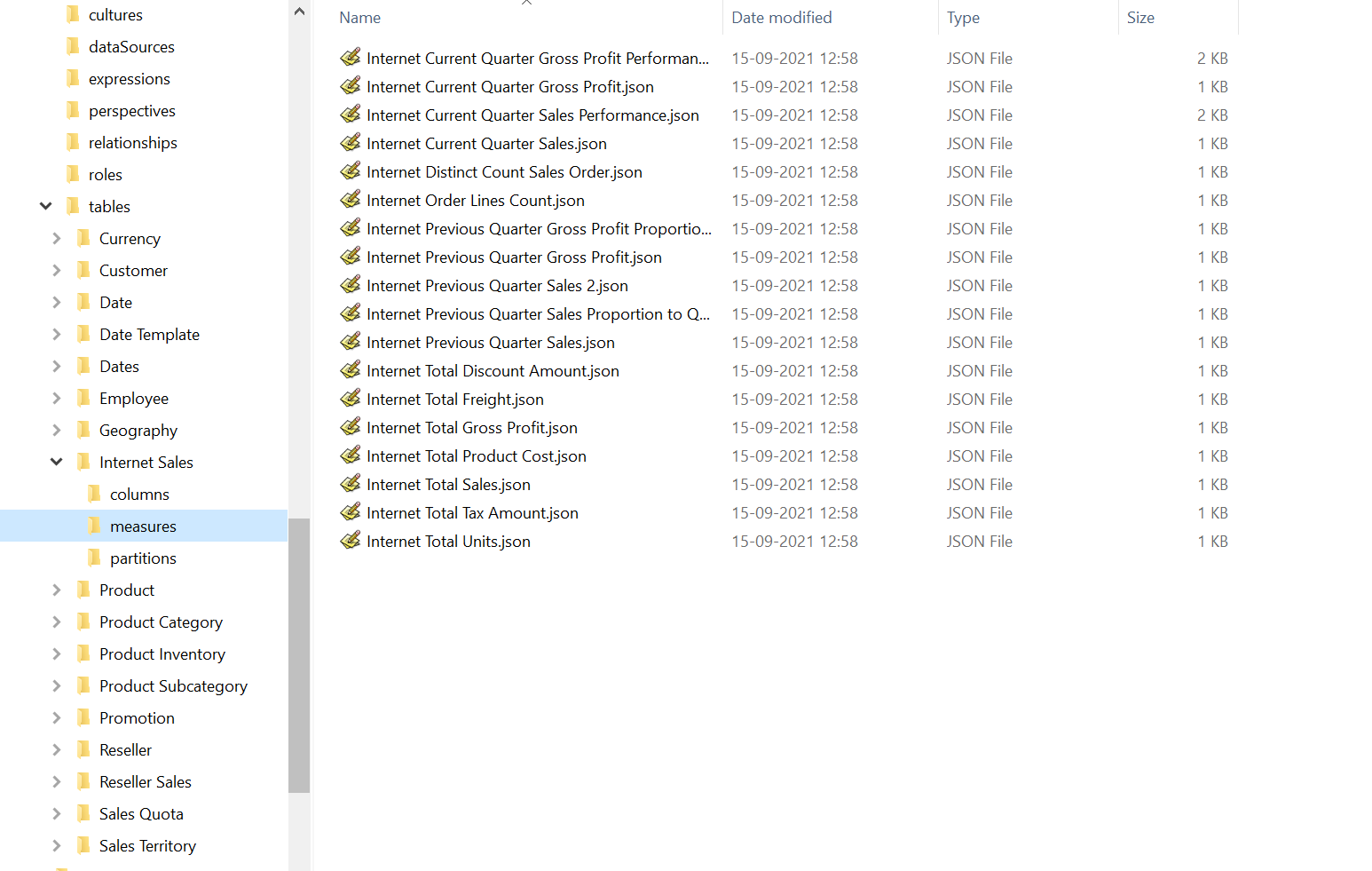
Los nombres de cada uno de los archivos que representan objetos TOM individuales se basan simplemente en la propiedad Name del propio objeto. El nombre del archivo "raíz" es Database.json, por eso a veces nos referimos al formato de almacenamiento basado en carpetas simplemente como Database.json.
Ventajas de usar Guardar en carpeta
A continuación se muestran algunas de las ventajas de almacenar los metadatos del modelo tabular en este formato basado en carpetas:
- Muchos archivos pequeños funcionan mejor con muchos sistemas de control de versiones que unos pocos archivos grandes. Por ejemplo, Git almacena instantáneas de los archivos modificados. Solo por este motivo ya tiene sentido que representar el modelo como varios archivos más pequeños sea mejor que almacenarlo como un único archivo grande.
- Evita conflictos cuando se reordenan los arrays. Las listas de tablas, medidas, columnas, etc., se representan como arrays en el JSON de Model.bim. Sin embargo, el orden de los objetos dentro del array no importa. No es raro que los objetos se reordenen durante el desarrollo del modelo, por ejemplo, debido a operaciones de cortar y pegar, etc. Con Guardar en carpeta, los objetos del array se almacenan como archivos individuales, por lo que ya no se hace seguimiento de cambios en los arrays y se reduce el riesgo de conflictos de fusión.
- Distintos desarrolladores rara vez modifican el mismo archivo. Mientras los desarrolladores trabajen en partes separadas del Data model, rara vez modificarán los mismos archivos, lo que reduce el riesgo de conflictos de fusión.
Inconvenientes de usar Guardar en carpeta
Tal y como está ahora, la única desventaja de almacenar los metadatos del modelo tabular en un formato basado en carpetas es que este formato solo lo utiliza Tabular Editor. En otras palabras, no puedes cargar directamente los metadatos del modelo en Visual Studio desde el formato basado en carpetas. En su lugar, tendrías que convertir temporalmente el formato basado en carpetas al formato Model.bim, lo cual, por supuesto, puedes hacer con Tabular Editor.
Configurar Guardar en carpeta
Una misma solución rara vez encaja en todos los casos. Tabular Editor tiene varias opciones de configuración que afectan a cómo se serializa un modelo en la estructura de carpetas. En Tabular Editor 3, puedes encontrar la configuración general en Herramientas > Preferencia > Guardar en carpeta. Una vez cargado un modelo en Tabular Editor, puedes encontrar la configuración específica que se aplica a ese modelo en Modelo > Opciones de serialización.... La configuración que se aplica a un modelo específico se almacena como una anotación dentro del propio modelo, para garantizar que se use la misma configuración independientemente del usuario que cargue y guarde el modelo.
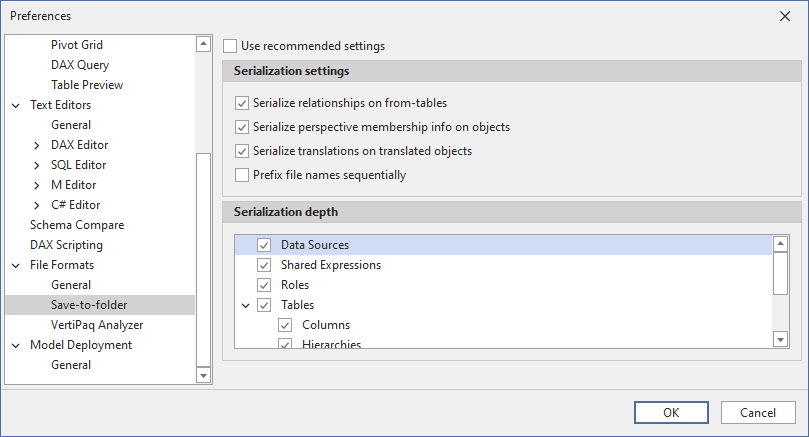
Configuración de serialización
- Usar la configuración recomendada: (Predeterminado: activado) Cuando esta opción está activada, Tabular Editor usa la configuración predeterminada la primera vez que guarda un modelo como una estructura de carpetas.
- Serializar relaciones en las tablas de origen: (Predeterminado: desactivado) Cuando esta opción está activada, Tabular Editor almacena las relaciones como una anotación en la tabla del "lado de origen" (normalmente, la tabla de hechos) de la relación, en lugar de almacenarlas a nivel de modelo. Esto resulta útil en las primeras fases de desarrollo de un modelo, cuando los nombres de las tablas aún cambian con bastante frecuencia.
- Serializar información de pertenencia a perspectivas en los objetos: (Predeterminado: desactivado) Cuando esta opción está activada, Tabular Editor almacena la información sobre a qué perspectivas pertenece un objeto (tabla, columna, jerarquía, medida) como una anotación en ese objeto, en lugar de almacenar la información a nivel de perspectiva. Esto resulta útil cuando los nombres de los objetos pueden cambiar, pero los nombres de las perspectivas ya están finalizados.
- Serializar traducciones en los objetos traducidos: (Predeterminado: desactivado) Cuando esta opción está activada, Tabular Editor almacena las traducciones de metadatos como una anotación en cada objeto traducible (tabla, columna, jerarquía, nivel, medida, etc.), en lugar de almacenarlas a nivel de configuración regional. Esto resulta útil cuando los nombres de los objetos pueden cambiar.
- Anteponer números secuenciales a los nombres de archivo: (Predeterminado: desactivado) En los casos en los que quieras conservar el orden de metadatos de los miembros del array (como el orden de las columnas en una tabla), puedes activar esta opción para que Tabular Editor anteponga a los nombres de archivo un número entero secuencial basado en el índice del objeto en el array. Esto resulta útil si usas la funcionalidad de drillthrough predeterminada de Excel y quieres que las columnas aparezcan en un orden concreto en el drillthrough.
Note
El propósito principal de las opciones de configuración descritas arriba es reducir el número de conflictos de fusión durante el desarrollo del modelo, ajustando cómo y dónde se almacenan determinados metadatos del modelo. En las primeras fases del desarrollo del modelo, es habitual que los objetos se renombren con frecuencia. Si un modelo ya tiene traducciones de metadatos especificadas, cada cambio de nombre de un objeto provocaría al menos dos cambios: uno en el objeto que se renombra y otro por cada configuración regional que defina una traducción en ese objeto. Cuando se activa Serializar traducciones en objetos traducidos, solo habría un cambio en el objeto que se renombra, ya que ese objeto también incluye los valores traducidos (puesto que esta información se almacenaría como una anotación).
Profundidad de serialización
La lista de verificación te permite especificar qué objetos se serializarán como archivos individuales. Ten en cuenta que algunas opciones (perspectivas, traducciones, relaciones) pueden no estar disponibles, en función de la configuración indicada anteriormente.
En la mayoría de los casos, se recomienda serializar siempre los objetos al nivel más bajo. Sin embargo, puede haber casos especiales en los que no se necesite este nivel de detalle.
Power BI y control de versiones
Como se mencionó anteriormente, integrar un archivo de Report de Power BI (.pbix) o una plantilla de Power BI (.pbit) en el control de versiones no permite el desarrollo en paralelo ni la resolución de conflictos, ya que estos archivos usan un formato binario. Al mismo tiempo, debemos ser conscientes de las limitaciones actuales al usar Tabular Editor (u otras herramientas de terceros) con Power BI Desktop o con el punto de conexión XMLA de Power BI, respectivamente.
Estas limitaciones son:
- Al usar Tabular Editor como herramienta externa para Power BI Desktop, no se admiten todas las operaciones de modelado.
- Tabular Editor puede extraer metadatos del modelo desde un archivo .pbix cargado en Power BI Desktop o directamente desde un archivo .pbit en disco, pero no existe ninguna forma compatible de actualizar los metadatos del modelo en un archivo .pbix o .pbit fuera de Power BI Desktop.
- Una vez que se realiza cualquier cambio en un Dataset de Power BI a través del punto de conexión XMLA, ese Dataset ya no se puede descargar como archivo .pbix.
Para habilitar el desarrollo en paralelo, debemos poder almacenar los metadatos del modelo en uno de los formatos basados en texto (JSON) mencionados anteriormente (Model.bim o Database.json). No hay forma de "recrear" un archivo .pbix o .pbit a partir del formato basado en texto, así que una vez que decidamos seguir esta ruta, ya no podremos usar Power BI Desktop para editar el Data model. En su lugar, tendremos que apoyarnos en herramientas que puedan usar el formato basado en JSON, que es precisamente el propósito de Tabular Editor.
Warning
Si no tienes acceso a un Workspace de Power BI Premium (ya sea capacidad Premium o Premium-Per-User), no podrás publicar los metadatos del modelo almacenados en los archivos JSON, ya que esta operación requiere acceso al punto de conexión XMLA.
Note
Power BI Desktop sigue siendo necesario para crear la parte Visual del Report. Es una buena práctica separar siempre los Report de los modelos. Si tienes un archivo de Power BI existente que incluye ambos, esta entrada de blog (vídeo) describe cómo dividirlo en un archivo de modelo y un archivo de Report.
Tabular Editor y git
Git es un sistema de control de versiones distribuido, gratuito y de código abierto, diseñado para gestionar desde proyectos pequeños hasta proyectos muy grandes con rapidez y eficiencia. Es el sistema de control de versiones más popular actualmente y está disponible mediante varias opciones alojadas, como Azure DevOps, GitHub, GitLab y otras.
Una descripción detallada de Git queda fuera del alcance de este artículo. Aun así, hay muchos recursos disponibles en Internet si quieres aprender más. Recomendamos el libro Pro Git como referencia.
Note
Actualmente, Tabular Editor 3 no tiene ninguna integración con Git ni con otros sistemas de control de versiones. Para administrar tu repositorio de Git, realizar commits de cambios de código, crear ramas, etc., tendrás que usar la línea de comandos de Git u otra herramienta, como Visual Studio Team Explorer o TortoiseGit.
Como se mencionó antes, recomendamos usar la opción Guardar en carpeta de Tabular Editor al guardar los metadatos del modelo en un repositorio de código de Git.
Estrategia de ramificación
A continuación, se analiza qué estrategias de ramificación conviene usar al desarrollar modelos tabulares.
La estrategia de ramificación determinará cómo será el flujo de trabajo diario de desarrollo y, en muchos casos, las ramas se alinearán directamente con las metodologías que utilice tu equipo. Por ejemplo, al usar el proceso ágil en Azure DevOps, tu backlog constaría de Épicas, Características, Historias de usuario, Tareas y Defectos.
En la terminología ágil, una Historia de usuario es una unidad de trabajo entregable y comprobable. La Historia de usuario puede constar de varias Tareas, que son unidades de trabajo más pequeñas que deben realizarse, normalmente por un desarrollador, antes de que la Historia de usuario pueda entregarse. En un mundo ideal, todas las Historias de usuario se desglosan en tareas manejables, cada una de las cuales requiere solo un par de horas para completarse, sumando como mucho unos pocos días para toda la Historia de usuario. Esto haría que una Historia de usuario fuera una candidata ideal para lo que se conoce como una rama temática, en la que el desarrollador podría hacer uno o varios commits por cada una de las tareas dentro de la Historia de usuario. Una vez que se han completado todas las tareas, querrás entregar la Historia de usuario al cliente. En ese momento, la rama temática se fusiona en una rama de entrega (por ejemplo, una rama "Test") y el código se despliega en un entorno de pruebas.
Determinar una estrategia de ramificación adecuada depende de muchos factores. En general, Microsoft recomienda la estrategia Trunk-based Development (vídeo) para la entrega ágil y continua de incrementos pequeños. La idea principal es crear ramas a partir de la rama "Main" para cada nueva funcionalidad o corrección de errores (consulta la imagen a continuación). Los procesos de revisión de código se aplican mediante pull requests desde las ramas de características hacia "Main" y, mediante la característica Branch Policy de Azure DevOps, podemos configurar reglas que exijan que el código se compile sin errores antes de poder completar un pull request.
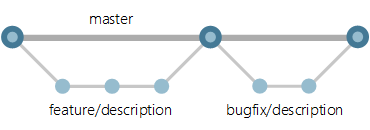
Trunk-based Development
Sin embargo, este tipo de estrategia puede no ser viable para equipos de desarrollo de Business Intelligence, por varias razones:
- Las nuevas características suelen requerir pruebas y validación prolongadas por parte de los usuarios de negocio, lo que puede tardar varias semanas en completarse. Por lo tanto, probablemente necesitarás un entorno de pruebas orientado al usuario.
- Las soluciones de BI son de varios niveles y, por lo general, constan de una capa de Data Warehouse con ETL, una capa de Master Data Management, una capa semántica y Report. Existen dependencias entre estas capas, lo que complica aún más las pruebas y el despliegue.
- El equipo de BI puede ser responsable de desarrollar y mantener varios modelos semánticos diferentes, que dan servicio a distintas áreas del negocio (Ventas, Inventario, Logística, Finanzas, RR. HH., etc.), en diferentes fases de madurez y a distinto ritmo de desarrollo.
- ¡El aspecto más importante de una solución de BI son los datos! Como desarrollador de BI, no tienes el lujo de limitarte a extraer el código del control de versiones, pulsar F5 y tener una solución completa en funcionamiento en los pocos minutos que se tarda en compilarlo. Tu solución necesita datos, y esos datos deben cargarse, pasar por un proceso de ETL o procesarse a través de varias capas hasta llegar al usuario final. Incluir los datos en tus flujos de trabajo de DevOps podría disparar los tiempos de compilación y despliegue de minutos a horas, o incluso a días. En algunos escenarios, puede que ni siquiera sea posible, debido a limitaciones de recursos o de presupuesto.
No cabe duda de que un equipo de BI se beneficiaría de una estrategia de ramificación que admita el desarrollo en paralelo en cualquiera de las capas de la solución completa de BI, de modo que pueda mezclar y combinar las funcionalidades que estén listas para probar. Pero, especialmente por el último punto de la lista anterior, tenemos que pensar bien cómo vamos a manejar los datos. Por ejemplo, si añadimos un nuevo atributo a una dimensión, ¿queremos que la dimensión se cargue automáticamente como parte de nuestras canalizaciones de compilación y despliegue? Si cargar una dimensión así solo lleva unos minutos, probablemente no haya problema; pero ¿qué pasa si estamos añadiendo una nueva columna a una tabla de hechos con miles de millones de filas? Y si los desarrolladores trabajan en nuevas funcionalidades en paralelo, ¿debería cada desarrollador tener su propia base de datos de desarrollo o cómo evitamos, si no, que se pisen entre sí en una base de datos compartida?
No hay una respuesta fácil a las preguntas anteriores, especialmente si se tienen en cuenta todos los niveles de una solución de BI y las distintas combinaciones y flujos de trabajo preferidos por los equipos de BI de todo el mundo. Además, cuando entremos en la automatización real de compilación, despliegue y pruebas, nos centraremos principalmente en Analysis Services. Las capas de ETL y de base de datos tienen sus propios retos desde una perspectiva de DevOps, que quedan fuera del alcance de este artículo. Pero antes de continuar, veamos otra estrategia de ramificación y cómo podría adoptarse en los flujos de trabajo de BI.
Ramificación de GitFlow y entornos de despliegue
La estrategia descrita a continuación se basa en GitFlow de Vincent Driessen.
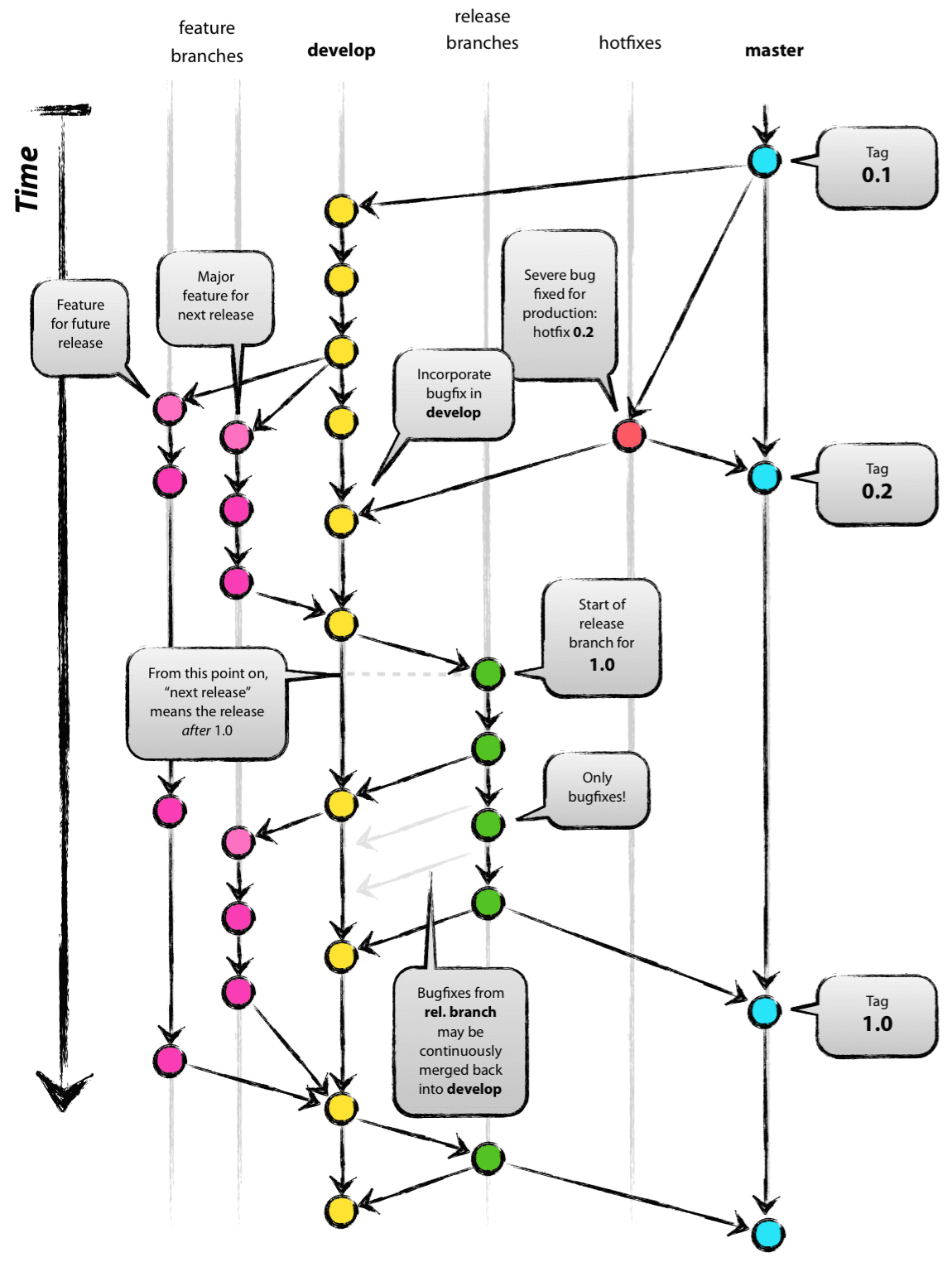
Implementar una estrategia de ramificación como esta puede ayudar a resolver algunos de los problemas de DevOps habituales en equipos de BI, siempre que dediques algo de tiempo a definir cómo se correlacionan las ramas con tus entornos de despliegue. En un mundo ideal, necesitarías al menos 4 entornos distintos para dar soporte completo a GitFlow:
- El entorno de producción, que siempre debería contener el código del HEAD de la rama master.
- Un entorno canary, que siempre debería contener el código del HEAD de la rama develop. Aquí es donde normalmente programas despliegues nocturnos y ejecutas las pruebas de integración para asegurarte de que las funcionalidades que entrarán en la próxima versión para producción funcionen bien juntas.
- Uno o varios entornos de UAT donde tú y los usuarios de negocio probáis y validáis nuevas funcionalidades. El despliegue se hace directamente desde la rama de funcionalidad que contiene el código que debe probarse. Necesitarás varios entornos de prueba si quieres probar varias funcionalidades nuevas en paralelo. Con un poco de coordinación, suele bastar con un único entorno de pruebas, siempre que consideres cuidadosamente las dependencias entre tus capas de BI.
- Uno o varios entornos sandbox en los que tú y tu equipo pueden desarrollar nuevas funcionalidades sin afectar a ninguno de los entornos anteriores. Al igual que con el entorno de pruebas, normalmente basta con tener un único entorno sandbox compartido.
Tenemos que recalcar que, en realidad, no existe una solución que sirva para todo. Quizá no estés construyendo tu solución en la nube y, por tanto, no tengas la escalabilidad o flexibilidad para aprovisionar nuevos recursos en segundos o minutos. O quizá tus volúmenes de datos sean muy grandes, lo que hace poco práctico replicar entornos por limitaciones de recursos, coste o tiempo. Antes de continuar, asegúrate también de preguntarte si de verdad necesitas dar soporte al desarrollo y las pruebas en paralelo. Esto rara vez se da en equipos pequeños con pocas partes interesadas; en ese caso, aún puedes beneficiarte de CI/CD, pero la estrategia de ramificación GitFlow puede ser excesiva.
Aunque necesites dar soporte al desarrollo en paralelo, es posible que varios desarrolladores compartan sin problema el mismo entorno de desarrollo o sandbox, sin demasiadas complicaciones. En particular, para modelos tabulares, recomendamos que los desarrolladores sigan usando bases de datos de Workspace individuales para evitar "pisarse" entre ellos.
Flujo de trabajo habitual
Suponiendo que ya tienes un repositorio Git configurado y alineado con tu estrategia de ramificación, añadir el "código fuente" de tu modelo tabular al repositorio consiste simplemente en usar Tabular Editor para guardar los metadatos en una nueva rama de un repositorio local. Luego, preparas y haces commit de los nuevos archivos, haces push de tu rama al repositorio remoto y creas un pull request para fusionar tu rama en la rama principal.
El flujo de trabajo exacto depende de tu estrategia de ramificación y de cómo se hayan configurado tus repositorios Git. En general, el flujo de trabajo sería algo así:
- Antes de empezar a trabajar en una nueva funcionalidad, crea una nueva rama de funcionalidad en git. En un escenario de desarrollo basado en trunk, necesitarías los siguientes comandos de Git para hacer checkout de la rama principal, obtener la última versión del código y crear desde ahí la rama de funcionalidad:
git checkout main git pull git checkout -b "feature\AddTaxCalculation" - Abre los metadatos de tu modelo desde el repositorio git local en Tabular Editor. Idealmente, usa una base de datos de Workspace para facilitar las pruebas y la depuración del código DAX.
- Realiza los cambios necesarios en tu modelo usando Tabular Editor. Guarda los cambios de forma continua (CTRL+S). Haz commit de los cambios de código en git con regularidad después de guardar, para evitar perder trabajo y mantener un historial completo de todos los cambios realizados:
git add . git commit -m "Description of what was changed and why since last commit" git push - Si no usas una base de datos de Workspace, utiliza la opción Model > Deploy... de Tabular Editor para desplegar en un entorno sandbox o de desarrollo, y así probar los cambios realizados en los metadatos del modelo.
- Cuando hayas terminado y todo el código se haya confirmado y enviado al repositorio remoto, envía una solicitud de incorporación de cambios para que tu código quede integrado con la rama principal. Si se produce un conflicto de fusión, tendrás que resolverlo localmente; por ejemplo, con Visual Studio Team Explorer o simplemente abriendo los archivos .json en un editor de texto para resolver los conflictos (Git inserta marcadores de conflicto para indicar qué partes del código tienen conflictos).
- Una vez resueltos todos los conflictos, puede haber un proceso de revisión de código, la ejecución automatizada de compilaciones y pruebas basada en las políticas de rama, etc., para completar la solicitud de incorporación de cambios. Sin embargo, esto depende de tu estrategia de ramificación y de la configuración general.
En los siguientes artículos presentamos más detalles sobre cómo configurar las políticas de rama de Git, configurar canalizaciones automatizadas de compilación e implementación, etc., con Azure DevOps. Se pueden usar técnicas similares en otros entornos de compilación automatizada y de alojamiento de Git, como TeamCity, GitHub, etc.
Siguientes pasos
- @powerbi-cicd
- @as-cicd
- Optimización del flujo de trabajo de desarrollo con el modo del área de trabajo